
Page 34 - 2025年第56卷第6期
P. 34
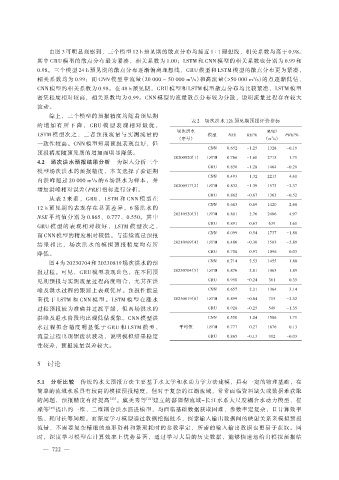
由图 3 可明显观察到,三个模型 12 h 预见期的散点分布均接近 1∶1 理想线,相关系数均高于 0.98。
其中 GRU 模型的散点分布最为紧凑,相关系数为 1.00;LSTM 和 CNN 模型的相关系数也分别为 0.99 和
0.98。三个模型 24 h 预见期的散点分布逐渐偏离理想线,GRU 模型和 LSTM 模型的散点分布更为紧凑,
相关系数均为 0.99;而 CNN 模型中流量(20 000 ~ 50 000 m³/s)和高流量(>50 000 m³/s)的点逐渐低估,
CNN 模型的相关系数为 0.98。在 48 h 预见期,GRU 模型和 LSTM 模型散点分布均比较紧凑,LSTM 模型
密集程度相对较高,相关系数均为 0.99。CNN 模型的流量散点分布较为分散,说明流量过程存在较大
波动。
综上,三个模型的预报精度均随着预见期
表 2 场次洪水 12h 预见期预报评价指标
的 增 加 有 所 下 降 , GRU 模 型 表 现 相 对 最 优 ,
场次洪水 MAE/
LSTM 模型次之,二者预报流量与实测流量的 模型 NSE RE/% PRE/%
(序号) (m /s)
3
一致性较高。CNN 模型短期预报表现良好,但
CNN 0.652 -1.25 1328 -0.19
预报精度随预见期的增加而明显降低。
20200820(1) LSTM 0.766 -1.60 2713 1.71
4.2 场次洪水预报结果分析 为深入分析三个
GRU 0.850 -1.28 1464 -0.28
模型场次洪水的预报精度,本文选择了验证期
CNN 0.493 1.32 2213 4.61
内洪峰超过 20 000 m³/s 的 6 场洪水为样本,并
20200917(2) LSTM 0.832 -1.39 1573 -2.37
增加洪峰相对误差(PRE)指标进行分析。
GRU 0.862 -0.67 1363 -0.52
从 表 2 来 看 , GRU、 LSTM 和 CNN 模 型 在
12 h 预见期的表现存在显著差异,6 场洪水的 CNN 0.683 0.89 1420 2.68
20210520(3) LSTM 0.801 2.76 2486 4.97
NSE 平均值分别为 0.865、0.777、0.550。其中
GRU 模 型 的 表 现 相 对 较 好 , LSTM 模 型 次 之 , GRU 0.891 0.67 639 1.61
而 CNN 模型的精度相对较低。与连续流量预报 CNN 0.099 0.54 1737 -1.88
结 果 相 比 , 场 次 洪 水 的 模 拟 预 报 精 度 均 有 所 20210909(4) LSTM 0.486 -0.30 1503 -2.89
降低。 GRU 0.708 0.97 1096 0.03
图 4 为 20230704 和 20230819 场次洪水的预 CNN 0.714 2.53 1455 1.88
报过程。可见,GRU 模型表现出色,在不同预 20230704(5) LSTM 0.876 2.81 1063 1.89
见期预报与实测流量过程高度吻合,尤其在洪 GRU 0.950 -0.24 361 0.35
峰及洪水过程的跟踪上表现优异。预报性能显 CNN 0.657 2.21 1364 3.14
著 优 于 LSTM 和 CNN 模 型 。 LSTM 模 型 在 涨 水 20230819(6) LSTM 0.899 -0.64 715 -2.52
过程预报较为准确并过渡平缓,但两场洪水的 GRU 0.928 -0.25 549 -1.35
洪峰及退水阶段均出现低估现象。CNN 模型洪 CNN 0.550 1.04 1586 1.71
水过程拟合精度明显低于 GRU 和 LSTM 模型, 平均值 LSTM 0.777 0.27 1676 0.13
流量过程出现锯齿状波动,说明模拟结果稳定 GRU 0.865 -0.13 912 -0.03
性较差,预报流量误差较大。
5 讨论
5.1 分析比较 传统的水文预报方法主要基于水文学和水动力学方法建模,具有一定的物理基础,在
简单的流域水系具有较高的模拟预报精度,但对于复杂的江湖流域,常常面临资料缺失或数据难获取
的问题,预报精度有待提高 [23] 。虞美秀等 [24] 建立的鄱阳湖流域-长江水系大尺度耦合水动力模型、崔
璨等 [25] 提出的一维、二维耦合洪水演进模型,均面临基础数据获取困难、参数率定复杂,且计算效率
低、耗时长等问题。而深度学习模型通过数据挖掘技术,探索输入输出数据间的映射关系来模拟预报
流量,不需要复杂精细的地形资料和繁琐耗时的参数率定,所需的输入输出数据也更易于获取。同
时,深度学习模型在计算效率上优势显著,通过学习大量的历史数据,能够快速地给出模拟预报结
— 722 —