
Page 63 - 水利学报2025年第56卷第3期
P. 63
3.2 领域实体抽取 实体是本体概念的实例化表达,水利防汛抢险实体隐含在形式各异的文本中。要
抽取实体信息,需要准确找出实体起始与结束位置,然后判断实体类型。基于隐马尔科夫和条件随机
场 CRF的统计学习方法,依靠词语本身特征(例如词性、标志性词语等)设置规则抽取文本实体 [25 - 26] ,
但基于规则的实体抽取方法可扩展性和可移植性较差。因此,以长短期记忆网络 LSTM 为代表的更普
适的深度学习实体抽取方法不断涌现 [27 - 28] ,随后融合统计学方法与深度学习优势的 LSTM- CRF模型
成为了实体抽取主流方法 [29] 。无论采用哪种实体抽取方法,都应尽力保证文本表示过程语义不变,例
如,文本表示后,“管涌” 与 “流土” 的相似度应比 “管涌” 与 “混凝土” 的相似度更高。上述方法
只能从有限的数据中学习知识表达模式,模型文本语义表示能力不足,当数据匮乏时难以保证实体抽
取的准确度。
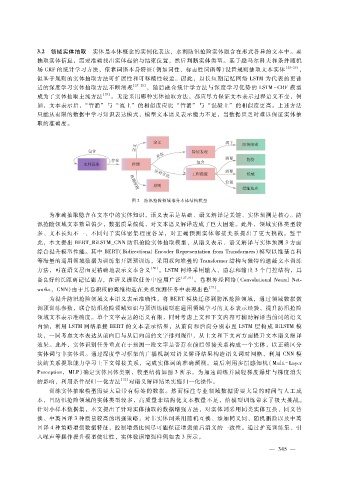
图 2 防汛抢险领域部分本体结构模型
为准确抽取隐含在文本中的实体知识,语义表示是基础、语义解译是关键、实体预测是核心。防
汛抢险领域文本数量偏少,数据质量偏低,对文本语义解译造成了巨大困难。此外,领域实体类型较
多、文本长短不一、不同句子实体密集程度各异,对正确预测实体邻接关系提出了更大挑战。鉴于
此,本文提出 BERT_BiLSTM_CNN防汛抢险实体抽取模型,从语义表示、语义解译与实体预测 3方面
综合提升模型性能。其中 BERT(BidirectionalEncoderRepresentationfrom Transformers)模型以维基百科
等海量的通用领域数据为训练集开展预训练,采用双向堆叠的 Transformer结构与独特的遮蔽文本训练
方法,可在语义层面更精确地表示文本含义 [30] 。LSTM网络采用输入、遗忘和输出 3个门控结构,具
备良好的长距离记忆能力,在语义提取任务中应用广泛 [27,31] 。卷积神经网络(ConvolutionalNeuralNet
works ,CNN)由于其卷积核的高维构造在关系预测任务中表现出色 [22] 。
为提升防汛抢险领域文本语义表示准确性,将 BERT模块迁移到防汛抢险领域,通过领域数据微
调预训练参数,联合防汛抢险领域知识与预训练模型在通用领域学习的文本表示经验,提升防汛抢险
领域文本表示准确度。单个文字表达的语义有限,同时考虑上文和下文内容可辅助解译当前词的语义
内涵,利用 LSTM网络承接 BERT的文本表示结果,从前向和后向分别布置 LSTM 层构成 BiLSTM 模
块,一同考虑文本表达从前向后与从后向前的文字排列规律,从上文和下文两方面提升文本语义解译
效果。此外,实体识别任务重点在于预测一段文字是否存在前后邻接关系构成一个实体,以正确区分
实体词与非实体词。通过深度学习框架的广播机制对语义解译结果构造语义词对网格,利用 CNN模
块的关系提取能力学习上下文邻接关系,完成实体词的准确预测。最后利用多层感知机( Multi - Layer
Perception,MLP)确定实体具体类别,模型结构如图 3所示。为加速训练并减轻梯度爆炸与梯度消失
的影响,利用条件层归一化方法 [32] 对语义解译结果实施归一化操作。
训练实体抽取模型需要大量带有标签的数据。然而标注专业领域数据需要大量的时间与人工成
本,且防汛抢险领域的实体类型较多,高质量非结构化文本数量不足,给模型训练带来了极大挑战。
针对小样本数据集,本文提出了针对实体抽取的数据增强方法,对实体词采用同类实体互换、同义替
换、中英回译 3种质量较高的增强策略,对非实体词采用随机互换、添加同义词、随机删除以及中英
回译 4种策略增强数据特征,控制增强比例尽可能保证增强前后语义的一致性。通过扩充训练集、引
入噪声等操作提升模型健壮性,实体数据增强样例如表 3所示。
— 3 4 5 —