
Page 127 - 2022年第53卷第6期
P. 127
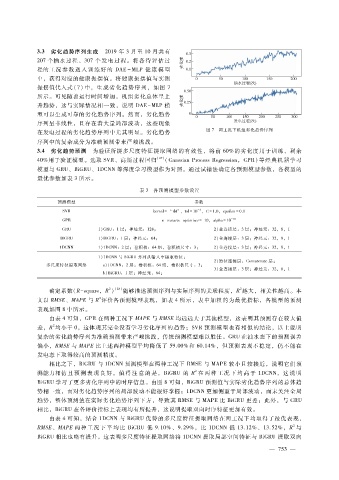
3.3 劣化趋势序列生成 2019年 3月至 10月共有
207个抽水过程、307个发电 过程。将各 待评估 过
程的工 况 参 数 送 入 训 练 好 的 DAE - MLP健 康 模 型
中,获得对应的健康振摆值。将健康振摆值与实测
振摆值代入式 ( 7)中,生 成劣 化趋势 序列,如图 7
所示。可见随着运行时间增加,机组劣化总体呈上
升趋势,这与实际情况相一致,说明 DAE - MLP模
型可以生成可靠的劣化趋势序列。然而,劣化趋势
序列呈非线性,且存在着大量局部波动,这些现象
图 7 两工况下机组劣化趋势序列
在发电过程的劣化趋势序列中尤其明显。劣化趋势
序列中的复杂成分为准确预测带来严峻挑战。
3.4 劣化趋势预测 为验证所提多尺度特征提取网络的有效性,将前 60%的劣化度用于训练,剩余
40%用于验证模型。选取 SVR、高斯过程回归 [27] (GaussianProcessRegression,GPR)等经典机器学习
模型与 GRU、BiGRU、1DCNN等深度学习模型作为对照。通过试错法确定各预测模型参数,各模型的
最优参数如表 3所示。
表 3 各预测模型参数设置
预测模型 参数
- 3
SVR kernel = ‘rbf’,tol = 10 ,C = 1.0,epsilon = 0.1
GPR n_restarts_optimizer =10,alpha = 10 - 10
GRU 1)GRU:1层;神经元:128; 2)全连接层:3层;神经元:32,8,1
BiGRU 1 )BiGRU:1层;神经元:64; 2)全连接层:3层;神经元:32,8,1
1DCNN 1 )1DCNN:2层;卷积核:64组,卷积核尺寸:3; 2)全连接层:3层;神经元:32,8,1
1)1DCNN与 BiGRU并列从输入中提取特征;
2)特征连接层:Concatenate层;
多尺度特征提取网络 a)1DCNN:2层;卷积核:64组,卷积核尺寸:3;
3)全连接层:3层;神经元:32,8,1
b)BiGRU:1层;神经元:64;
2
2 [28]
确定系数(R - square ,R) 能够描述预测序列与实际序列的关联程度,R越大,相关性越高。本
2
文以 RMSE、MAPE与 R评价各预测模型表现,如表 4所示,表中加粗的为最优指标,各模型的预测
表现如图 8中所示。
由表 4可知,GPR在两种工况下 MAPE与 RMSE均远远大于其他模型,这表明其预测存在较大偏
2
差,R均小于 0,这体现其完全没有学习劣化序列的趋势;SVR预测模型也有相似的结论,以上说明
复杂的劣化趋势序列为准确预测带来严峻挑战,传统预测模型难以胜任。GRU在抽水态下的预测误差
偏小,RMSE与 MAPE比上述两种模型平均降低了 59.00%和 60.14%,但预测表现不稳定,仍不能在
发电态下取得较高的预测精度。
相比之下,BiGRU与 1DCNN预测模型在两种工况下 RMSE与 MAPE较小且较接近,说明它们预
2
测能力相仿 且 预 测 表 现 良 好。值 得 注 意 的 是,BiGRU的 R 在 两 种 工 况 下 均 高 于 1DCNN, 这 说 明
BiGRU学习了更多劣化序列中的时序信息。由图 8可知,BiGRU预测值与实际劣化趋势序列的总体趋
势相一致,而对劣化趋势序列的局部波动不能很好掌握;1DCNN更加侧重于局部波动,而未关注全局
趋势,整体预测值在实际劣化趋势序列下方,导致其 RMSE与 MAPE比 BiGRU更差;此外,与 GRU
相比,BiGRU在各评价指标上表现均有所提升,这说明提取双向时序特征更加有效。
由表 4可知,结合 1DCNN与 BiGRU优势的多尺度特征提取网络在两工况下均取得了最优表现,
2
RMSE、MAPE两种 工 况 下 平 均 比 BiGRU低 9.10%、9.29%,比 1DCNN低 13.12%、13.52%,R 与
BiGRU相比也略有提升。这表明多尺度特征提取网络将 1DCNN提取局部空间特征与 BiGRU提取双向
— 7 5 3 —