
Page 143 - 2025年第56卷第1期
P. 143
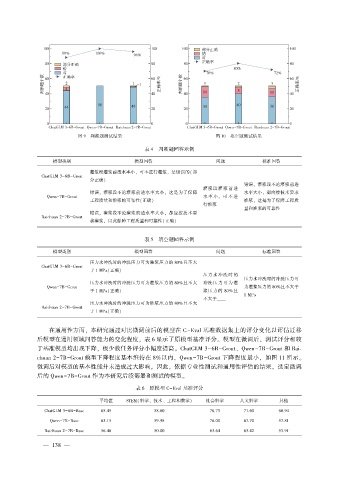
图 9 判断题测试结果 图 10 填空题测试结果
表 4 判断题回答示例
模型类别 模型回答 问题 标准回答
灌浆段灌浆前透水率小, 可不进行灌浆, 是错误的(部
ChatGLM 3-6B-Grout
分正确)
错误, 灌浆段不论灌浆前透
灌浆 段灌浆 前 透
错误, 灌浆段不论灌浆前透水率大小, 这是为了保障 水率大小, 都应按技术要求
Qwen-7B-Grout 水率 小, 可 不 进
工程质量和灌浆的可靠性(正确) 灌浆, 这是为了保障工程质
行灌浆
量和灌浆的可靠性
错误, 灌浆段不论灌浆前透水率大小, 都应按技术要
Baichuan 2-7B-Grout
求灌浆, 以此保障工程质量和可靠性(正确)
表 5 填空题回答示例
模型类别 模型回答 问题 标准回答
压力水冲洗时的冲洗压力可为灌浆压力的 80%且不大
ChatGLM 3-6B-Grout
于 1 MPa(正确)
压力 水冲洗 时 的
压力水冲洗时的冲洗压力可
压力水冲洗时的冲洗压力可为灌浆压力的 80%且不大 冲洗 压力可 为 灌
Qwen-7B-Grout 为灌浆压力的 80%且不大于
于 1 MPa(正确) 浆压力的 80% 且
1 MPa
不大于
压力水冲洗时的冲洗压力可为灌浆压力的 80%且不大
Baichuan 2-7B-Grout
于 1 MPa(正确)
在通用性方面, 本研究通过对比微调前后的模型在 C-Eval 基准数据集上的评分变化以评估迁移
后模型在通用领域问答能力的变化程度, 表 6 显示了原模型基准评分。 模型在微调后, 测试评分相较
于基准模型均出现下降, 极少数任务评分小幅度提高。 ChatGLM 3-6B-Grout、 Qwen-7B-Grout 和 Bai⁃
chuan 2-7B-Grout 模型下降程度基本维持在 8%以内, Qwen-7B-Grout 下降程度最小, 如图 11 所示。
微调后对模型的基本性能并未造成过大影响。 因此, 依据专业性测试和通用性评估的结果, 选定微调
后的 Qwen-7B-Grout 作为本研究后续部署和测试的模型。
表 6 原模型 C-Eval 基准评分
平均值 STEM(科学、 技术、 工程和数学) 社会科学 人文科学 其他
ChatGLM 3-6B-Base 65.45 58.60 76.73 71.60 60.94
Qwen-7B-Base 63.15 59.98 76.00 67.70 57.81
Baichuan 2-7B-Base 56.46 50.00 63.64 63.42 53.91
— 1 3 8 —