
Page 94 - 2025年第56卷第5期
P. 94
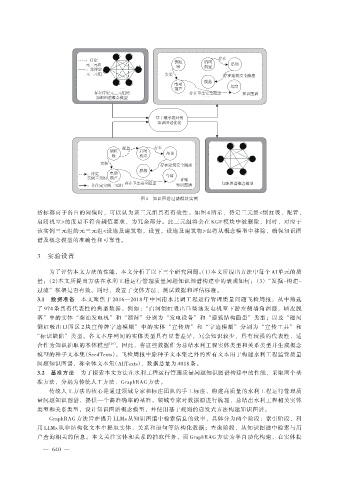
图 4 知识图谱过滤模块实例
指标都高于各自的阈值时,可以认为该三元组具有有效性。如图 4 所示,待定三元组<倒虹吸,配置,
启闭机室>的度量不符合阈值要求,为冗余部分。此三元组将会在 KGF 模块中被删除,同时,对应于
该实例三元组的元三元组<设施及建筑物,设置,设施及建筑物>也将从概念模型中移除,确保知识图
谱及概念模型的准确性和可靠性。
3 实验设置
为了评估本文方法的性能,本文分析了以下三个研究问题。(1)本文所提出方法中每个 AI 单元的质
量;(2)本文所提出方法在水利工程运行管理质量问题知识图谱构建中的表现如何;(3)“发掘-构建-
过滤”框架是否有效。同时,设置了变体方法、测试数据和评估标准。
3.1 数据准备 本文聚焦于 2016—2018 年中国南水北调工程运行管理质量问题飞检周报,从中筛选
了 974 条具有代表性的典型数据。例如:“白河倒虹吸出口柴油发电机室下游左侧墙角洇湿,墙皮脱
落”中的实体“柴油发电机”和“洇湿”分别为“发电设备”和“建筑结构隐患”类型;以及“磁河
倒虹吸出口园区 2 块宣传牌字迹模糊”中的实体“宣传牌”和“字迹模糊”分别为“宣传工具”和
“标识缺陷”类型。各文本序列间的实体类型具有显著差异,冗余知识较少,具有较强的代表性,适
合作为知识抽取的本体模型 [29] 。因此,将这些数据作为总结水利工程实体类型和关系类型并生成概念
模型的种子文本集(SeedTexts)。飞检周报中除种子文本集之外的所有文本用于构建水利工程监管质量
问题知识图谱,称全体文本集(AllTexts),数据总量为 4018 条。
3.2 基准方法 为了探索本文方法在水利工程运行管理质量问题知识图谱构建中的性能,采取两个基
准方法,分别为传统人工方法、GraphRAG 方法。
传统人工方法的核心是通过领域专家和标注团队的手工标注,构建高质量的水利工程运行管理质
量问题知识图谱,提供一个高准确率的基准。领域专家对数据源进行梳理,总结出水利工程相关实体
类型和关系类型,设计知识图谱概念模型,并使用基于规则的启发式方法构建知识图谱。
GraphRAG 方法旨在提升 LLMs 从知识图谱中检索信息的效率,具体分为两个阶段:索引阶段,利
用 LLMs 从非结构化文本中提取实体、关系和语句等结构化数据;查询阶段,从知识图谱中检索与用
户查询相关的信息。本文关注实体和关系的抽取任务,而 GraphRAG 方法为半自动化构建,在实体提
— 640 —