
Page 97 - 2025年第56卷第5期
P. 97
在该研究问题中,设计了三种变体方法(如 3.3 节所述)。为了降低人力成本,同 4.2 节方法,选取
384 个文本数据并将其应用到这三种变体方法中,收集各自的输出结果。随后,邀请 5 位专家对输出
结果进行了标注。为了评估不同专家的标注一致性,经过卡帕系数的衡量,专家之间的意见几乎完全
一致。
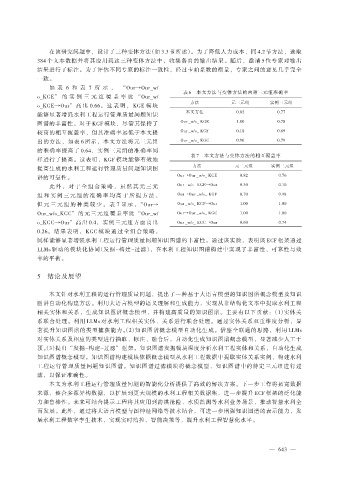
如 表 6 和 表 7 所 示 , “Our→Our_w/
表 6 本文方法与变体方法的两种三元组准确率
o_KGE” 的 实 例 三 元 组 覆 盖 率 比 “Our_w/
方法 元三元组 实例三元组
o_KGE→Our” 高 出 0.66。 这 表 明 , KGE 模 块
本文方法 0.82 0.77
能够显著增强水利工程运行管理质量问题知识
图谱的丰富性。对于 KGF 模块,尽管其保持了 Our _w/o_ KGE 1.00 0.78
较高的相互覆盖率,但其准确率远低于本文提 Our _w/o_ KGF 0.18 0.69
出的方法,如表 6 所示,本文方法将元三元组 Our _w/o_ KGC 0.90 0.79
的准确率提高了 0.64,实例三元组的准确率同
表 7 本文方法与变体方法的相互覆盖率
样进行了提高。这表明,KGF 模块能够有效地
提高生成的水利工程运行管理质量问题知识图 方法 元三元组 实例三元组
谱的可靠性。 Our→Our _w/o_ KGE 0.82 0.76
此 外 , 对 于 全 组 合 策 略 , 虽 然 其 元 三 元 Our _w/o_ KGE→Our 0.30 0.10
组 和 实 例 三 元 组 的 准 确 率 均 高 于 所 提 方 法 , Our→Our _w/o_ KGF 0.70 0.98
但 元 三 元 组 的 种 类 较 少 。 表 7 显 示 ,“Our→ Our _w/o_ KGF→Our 1.00 1.00
Our_w/o_KGC”的元三元组覆盖率比“Our_w/ Our→Our _w/o_ KGC 1.00 1.00
o_KGC→Our”高出 0.4,实例三元组方面高出 Our _w/o_ KGC→Our 0.60 0.74
0.26。结果表明,KGC 模块通过全组合策略,
同样能够显著增强水利工程运行管理质量问题知识图谱的丰富性。通过该实验,表明该 ECF 框架通过
LLMs 驱动的模块化协同(发掘-构建-过滤),在水利工程知识图谱构建中实现了丰富性、可靠性与效
率的平衡。
5 结论及展望
本文针对水利工程的运行管理质量问题,提出了一种基于大语言模型的知识图谱概念模型及知识
图谱自动化构建方法。利用大语言模型的语义理解和生成能力,实现从非结构化文本中提取水利工程
相关实体和关系,生成知识图谱概念模型,并构建高质量的知识图谱。主要有以下贡献:(1)实体关
系联合处理。利用 LLMs 对水利工程相关实体、关系进行联合处理。通过实体关系双重维度分析,显
著提升知识图谱的类型捕获能力。(2)知识图谱概念模型自动化生成。借鉴全联通的思路,利用 LLMs
对实体关系及相应的类型进行抽取、标注、融合后,自动化生成知识图谱概念模型,显著减少人工干
预。(3)提出“发掘-构建-过滤”框架。知识图谱发掘模块深度分析水利工程实体和关系,自动化生成
知识图谱概念模型。知识图谱构建模块依据概念模型从水利工程数据中提取实体关系实例,构建水利
工程运行管理质量问题知识图谱。知识图谱过滤模块将概念模型、知识图谱中的待定三元组进行过
滤,以保证准确性。
本文为水利工程运行管理质量问题的智能化分析提供了高效的解决方案。下一步工作将拓宽数据
来源,整合多源异构数据,以扩展到更大规模的水利工程相关数据集,进一步提升 ECF 框架的泛化能
力和鲁棒性。未来可结合提示工程将其应用到防洪抢险、水质监测等水利业务场景,推动智慧水利全
面发展。此外,通过将大语言模型与图神经网络等技术结合,可进一步增强知识图谱的表示能力,发
展水利工程数字孪生技术,实现实时监控、智能决策等,提升水利工程智慧化水平。
— 643 —