
Page 107 - 2025年第56卷第6期
P. 107
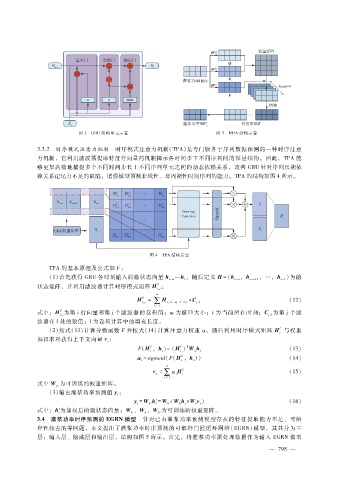
图 2 GRU结构单元示意 图 3 MHA结构示意
3.3.2 时序模式注意力机制 时序模式注意力机制(TPA)是专门服务于序列数据预测的一种时序注意
力机制,它利用滤波器提取特征行向量的机制揭示各时间步下不同序列间的深层结构。因此,TPA能
够更加高效地捕捉多个不同时间步长上不同序列单元之间的动态依赖关系,改善 GRU针对序列长期依
赖关系记忆力不足的缺陷,增强模型预测非线性、非周期性时间序列的能力。TPA的结构如图 4所示。
图 4 TPA结构示意
TPA的基本原理及公式如下:
( 1)首先获得 GRU各时刻输入的隐状态向量 h —h,随后定义 H= (h ,h t - ω + 1 ,…,h )为隐
t
t - ω
t - 1
t - ω
C
状态矩阵,并利用滤波器计算时序模式矩阵 H :
i ,j
ω
C
H = H i,(t - ω- 1 + l) × C j,l (12)
i,j ∑
l =1
C
式中:H 为第 i行向量和第 j个滤波器的卷积值;ω为窗口大小;t为当前所在时刻;C 为第 j个滤
i,j
j,l
波器在 l处的数值;l为卷积计算中的填充长度。
C
(2)按式(13)计算分数函数 F并按式(14)计算注意力权重 α ,随后利用时序模式矩阵 H 与权重
i
加权求和获得上下文向量 v:
t
C
T
C
F(H ,h) =(H )W h (13)
i t i a t
C
= sigmoid(F(H ,h)) (14)
α i i t
n
t ∑
v = α i H C (15)
i
i =1
式中 W 为可训练的权重矩阵。
a
( 3)输出灌浆功率预测值 y:
t
y= W h′ = W (W h+ W v) (16)
v t
t
h′ t
h′
h t
式中:h′为加权后的隐状态向量;W 、W 、W 为可训练的权重矩阵。
t h v h′
3.4 灌浆功率时序预测的 EGRN模型 针对已有灌浆功率预测模型存在的特征提取能力不足、可解
释性较差的等问题,本文提出了灌浆功率时序预测的可解释门控循环网络( EGRN)模型,其共分为三
层:输入层、隐藏层和输出层,结构如图 5所示。首先,将灌浆功率预处理数据作为输入 EGRN模型
— 7 9 5 —