
Page 111 - 2025年第56卷第6期
P. 111
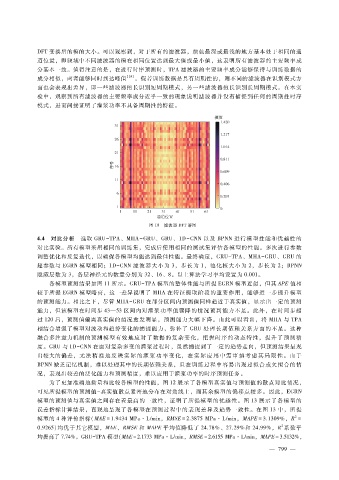
DFT变换后的模的大小。可以观察到,对于所有的滤波器,颜色最深或最浅的地方基本处于相同的通
道位置,即频域中不同滤波器的模在相同位置达到最大值或最小值,这表明所有滤波器的主要频率成
分基本一致。值得注意的是,在进行时序预测时,TPA滤波器的主要频率成分能够保持与训练数据的
成分相似,两者能够同时到达峰值 [24] 。假若训练数据是具有周期性的,则不同的滤波器在识别模式方
面也会表现出差异,即一些滤波器擅长识别短周期模式,另一些滤波器擅长识别长周期模式。在本实
验中,观察到所有滤波器的主要频率成分近乎一致的现象说明滤波器并没有捕捉到任何的周期性时序
模式,进而间接证明了灌浆功率不具备周期性的特征。
图 10 滤波器 DFT谱图
4.4 对比分析 选取 GRU - TPA、MHA - GRU、GRU、1D - CNN以及 BPNN进行模型性能和优越性的
对比实验。所有模型采用相同的训练集,完成后使用相同的测试集评估各模型的性能。多次进行参数
调整优化和反复迭代,以确保各模型均能达到最佳性能。最终确定,GRU - TPA、MHA - GRU、GRU的
超参数与 EGRN模型相同;1D - CNN滤波器大小为 3,步长为 1,池化核大小为 2,步长为 2;BPNN
隐藏层数为 3,各层神经元的数量分别为 32、16、8。以上算法学习率均设置为 0.001。
各模型预测结果如图 11所示。GRU - TPA模型的整体性能与所提 EGRN模型近似,但其 APE值相
较于所提 EGRN模型略高,这一差异说明了 MHA在特征提取阶段的重要作用,能够进一步提升模型
的预测能力。相比之下,尽管 MHA - GRU在部分区间内预测值同样趋近于真实值,显示出一定的预测
能力,但该模型在时间步 43—53区间内对灌浆功率值骤降的情况预判能力不足。此外,在时间步超
过 120后,预测值偏离真实值的情况愈发明显,预测能力大幅下降。由此可以看出,将 MHA与 TPA
相结合增强了模型对波动和趋势变化的捕捉能力,弥补了 GRU处理长期依赖关系方面的不足。这种
融合多注意力机制的预测模型有效地应对了数据的复杂变化,把握时序的动态特性,提升了预测精
度。GRU与 1D - CNN在面对复杂多变的灌浆过程时,虽然捕捉到了一定的趋势走向,但预测结果呈现
出较大的偏差,无法 精准 地反 映 实 际 的 灌 浆 功 率 变 化,在 实 际 应 用 中 需 审 慎 考 虑 其 局 限 性。由 于
BPNN缺乏记忆机制,难以处理其中的长期依赖关系,且在训练过程中容易出现过拟合或欠拟合的情
况,表现出较差的泛化能力和预测精度,难以应用于灌浆功率的时序预测任务。
为了更加准确地衡量和比较各模型的性能,图 12展示了各模型真实值与预测值的散点对比情况,
可见所提模型的预测值- 真实值散点紧密地分布在对角线上,而其余模型的偏移点较多。因此,EGRN
模型的预测值与真实值之间存在着最高的一致性,证明了所提模型的优越性。图 13展示了各模型的
误差指标计算结果,直观地呈现了各模型在预测过程中的表现差异及趋势一致性。在图 13中,所提
2
模型的 4种评价指标(MAE = 1.9434MPa·L?min,RMSE = 2.3875MPa·L?min,MAPE = 3.1309%,R =
2
0.9265)均优于其它模型,MAE、RMSE和 MAPE平均值降低了 24.78%、27.29%和 24.99%,R系数平
均提高了 7.74%。GRU - TPA模型(MAE = 2.1733MPa·L?min,RMSE = 2.6155MPa·L?min,MAPE = 3.5132%,
— 7 9 9 —