
Page 66 - 水利学报2021年第52卷第6期
P. 66
4.1 各预见时刻径流预报误差分布求解 基于 IGMM-Copula 模型中的分布拟合部分(此处称为 IGMM)
对各预见时刻径流预报误差经验分布进行拟合,首先需要确定各时刻预报误差的最优高斯混合数,
在原 GMM 模型中,由于没有相应的指标作为参考,作者偏向于参数较少,更容易求解的模型结构,
因此最终选取的高斯混合数为 K=2。现以 K=2 为起点,根据逐一列举法计算不同 K 值下的 AIC 及 BIC
的值。其计算结果如表 1。
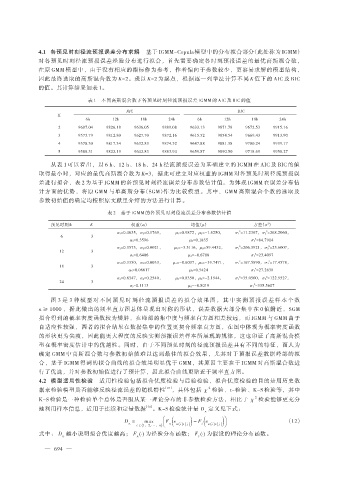
表 1 不同高斯混合数下各预见时刻径流预报误差 IGMM 的 AIC 及 BIC 的值
AIC BIC
K
6h 12h 18h 24h 6h 12h 18h 24h
2 9607.04 9826.18 9636.05 9889.08 9633.13 9871.78 9672.53 9915.16
3 9573.79 9812.80 9627.70 9872.16 9615.52 9854.54 9669.43 9913.90
4 9578.30 9817.34 9632.83 9874.52 9647.88 9881.38 9700.24 9939.17
5 9588.31 9822.19 9642.83 9883.94 9659.87 9890.50 9718.69 9958.27
从表 1 可以看出,以 6 h、12 h、18 h、24 h 径流预报误差为基础建立的 IGMM 在 AIC 及 BIC 的值
取得最小时,对应的最优高斯混合数为 K=3,据此可建立对应权重的 IGMM 对各预见时刻径流预报误
差进行拟合,表 2 为基于 IGMM 的各预见时刻径流误差分布参数估计值。为体现 IGMM 在误差分布估
计方面的优势,将原 GMM 与单高斯分布(SGM)作为比较模型。其中,GMM 高斯混合个数的选取及
参数初始值的确定均按照原文献里介绍的方法进行计算。
表 2 基于 IGMM 的各预见时刻径流误差分布参数估计值
2
预见时刻/h K 权重(α) 均值(μ) 方差(σ )
α 1=0.4635,α 2=0.1769, μ 1=0.9872,μ 2=-1.6250, σ 1 =11.2367,σ 2 =268.2060,
2
2
6 3
2
α 3=0.3596 μ 3=0.1835 σ 3 =84.7914
α 1=0.3573,α 2=0.0021, μ 1=-3.5116,μ 2=59.4452, σ 1 =206.3921,σ 2 =23.6007,
2
2
12 3
2
α 3=0.6406 μ 3=-0.6708 σ 3 =23.4097
α 1=0.3350,α 2=0.0033, μ 1=-0.6037,μ 2=-39.7471, σ 1 =167.5890,σ 2 =17.4578,
2
2
18 3
2
α 3=0.06617 μ 3=0.5424 σ 3 =27.2638
α 1=0.6347,α 2=0.2540, μ 1=0.8350,μ 2=-2.1944, σ 1 =35.0500,σ 2 =122.9527,
2
2
24 3
2
α 3=0.1113 μ 3=-0.8019 σ 3 =335.5607
图 3 是 3 种 模 型 对 不 同 预 见 时 刻 径 流 预 报 误 差 的 拟 合 效 果 图 , 其 中 实 测 预 报 误 差 样 本 个 数
n ≥ 1000 ,据此做出的频率直方图总体呈现出对称的形状,误差数据大部分集中在 0 值附近,SGM
拟合得到的概率密度函数较为矮胖,在峰部的集中度与频率直方图相差较远,而 IGMM 与 GMM 由于
自适应性较强,两者的拟合结果在数据集中的位置更契合频率直方图,在图中体现为概率密度函数
的形状更为尖瘦,因此能更大程度的反映实测预报误差样本所展现的规律,这也印证了高斯混合模
型在概率密度估计中的优越性。同时,由于不同预见时刻的径流预报误差具有不同的特征,而人为
确定 GMM 中高斯混合数与参数初始值难以达到最佳的拟合效果,尤其对于预报误差数据峰部的拟
合,基于 IGMM 得到的拟合曲线的拟合效果明显优于 GMM,其原因主要在于 IGMM 对高斯混合数进
行了优选,并对参数初始值进行了预计算,因此拟合曲线更贴近于频率直方图。
4.2 模型适用性检验 适用性检验包括拟合优度检验与后验检验,拟合优度检验的目的是用历史数
2
据来检验模型是否能够反映径流误差的随机特性 [23] ,具体包括 χ 检验、t-检验、K-S 检验等,其中
K-S 检验是一种检验单个总体是否服从某一理论分布的非参数检验方法,相比于 χ 检验能够更充分
2
地利用样本信息,适用于连续和定量数据 [24] 。K-S 检验统计量 D 定义见下式:
n
D = i ∈(1,2,⋯,n è æ çF e ) - F e ) ö ÷ ø (12)
max
n
n( x ( ) i t ( ) j
t( x ( ) i t ( ) j
)
式中: D 越小说明拟合优度越高; F (×) 为经验分布函数; F (×) 为假设的理论分布函数。
n
n
t
— 694 —