
Page 67 - 2022年第53卷第6期
P. 67
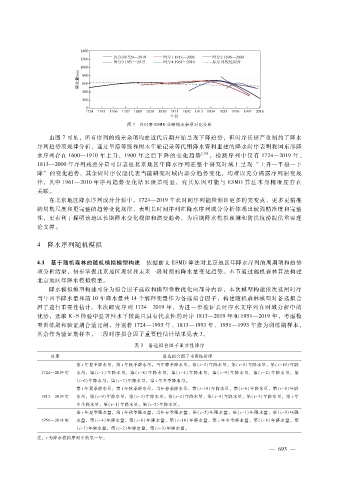
图 7 各时序 ESMD分解残差余项对比分析
由图 7可见,所有序列的残差余项均在近代后期开始呈现下降趋势,但时序长短严重制约了降水
序列趋势项规律分析,通过旱涝等级和树木年轮记录等代用降水资料重建的降水时序表明我国东部降
水序列存在 1600—1910年上升,1900年之后 下降的变化 趋势 [30] ,检 测 序列 中仅 有 1724—2019年、
1813—2000年序列残差分量可以表征北京地区年降水序列在整个研究时域上呈现 “上升—平稳—下
降” 的变化趋势,其余短时序仅能代表当前研究时域内部分趋势变化,均难以充分揭露序列演变规
律,其中 1961—2010年序列 趋势 变化 结果误差 明显,究其 原因 可能 与 ESMD算法 本 身 精 准 度 存 在
关联。
在北京地区降水序列成分分析中,1724—2019年长时间序列能检测出更多的突变点、更多更精准
的周期尺度和更完整的趋势变化规律,表明长时间序列在降水序列成分分析体现出较强精准度和完整
性,更有利于探明该地区长期降水变化规律和演变趋势,为后期降水模拟预测和防洪抗涝提供重要理
论支撑。
4 降水序列随机模拟
4.1 基于随机森林的随机模拟模型构建 依据前文 ESMD算法对北京地区年降水序列的周期项和趋势
项分析结果,初步掌握北京地区现状和未来一段时期的降水量变化趋势。本节通过随机森林算法构建
北京地区年降水模拟模型。
降水模拟模型构建可分为拟合因子选取和模型参数优化两部分内容,本次模型构建依次选用时序
当年四季降水量和前 10年降水量共 14个解释变量作为备选拟合因子,构建随机森林模型对备选拟合
因子进行重要性估计。本次研究序列 1724—2019年,为进一步验证长时序水文序列在时域分析中的
优势,选取 K - S检验中显著性水平较高且具有代表性的时序 1813—2019年和 1951—2019年,考虑模
型训练期和验证期合适比例,分别将 1724—1993年、1813—1993年、1951—1993年作为训练期样本,
其余作为验证期样本,三段时序拟合因子重要性估计结果见表 3。
表 3 备选拟合因子重要性排序
时序 备选拟合因子重要性排序
第 i年夏季降水量,第 i年秋季降水量,当年春季降水量,第(i - 3)年降水量,第(i - 5)年降水量,第(i - 10)年降
1724—2019年 水量,第(i - 1)年降水量,第(i - 8)年降水量,第(i - 4)年降水量,第(i - 9)年降水量,第(i - 2)年降水 量,第
( i - 6)年降水量,第(i - 7)年降水量,第 i年冬季降水量。
第 i年夏季降水量,第 i年秋季降水量,当年春季降水量,第(i - 10 )年降水量,第(i - 6 )年降水量,第(i - 8 )年降
1813—2019年 水量,第(i - 9)年降水量,第(i - 3)年降水量,第(i - 2)年降水量,第(i - 4)年降水量,第(i - 7)年降水量,第 i年
冬季降水量,第(i - 1)年降水量,第(i - 5)年降水量。
第 i年夏季降水量,第 i年秋季降水量,当年春季降水量,第(i - 5 )年降水量,第(i - 1 )年降水量,第(i - 9 )年降
1951—2019年 水量,第( i - 4 )年降水量,第(i - 6 )年降水量,第(i - 10 )年降水量,第 i年冬季降水量,第(i - 8 )年降水量,第
(i - 7 )年降水量,第(i - 2 )年降水量,第(i - 3 )年降水量。
注:i为降水模拟序列中的某一年。
— 6 9 3 —