
Page 68 - 2022年第53卷第6期
P. 68
选取表 3中重要性最高的 5个解释变量作为随机森林模型拟合因子。随机森林模型主要待定参数
有两个:子预报决策树模型数 N、决策树节点划分待选变量数 M,前者愈大,愈能有效抑制随机模拟
t
过程中的过拟合问题;后者愈大,愈能缩小子回归模型间的差异性。N通常取值应较大,M取值约等
t
于拟合因子总数的 1?3 [31] 。另结合数据实际情况将本次模型构建 N取值 2500,M取值 3。
t
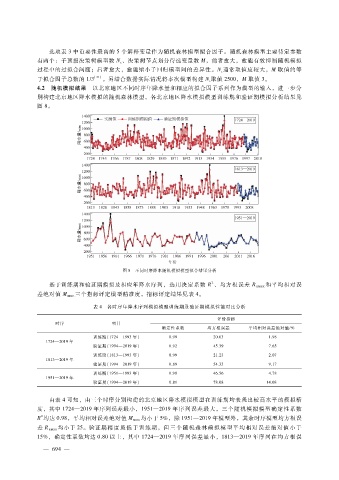
4.2 随机模拟结果 以北京地区不同时序年降水量和相应的拟合因子系列作为模型的输入,进一步分
别构建北京地区降水模拟的随机森林模型。各北京地区降水模拟模型训练期和验证期模拟分析结果见
图 8。
图 8 不同时序降水随机模拟模型拟合结果分析
2
基于训练期和验证期模拟及相应年降水序列,选用决定系数 R、均方根误差 R 和平均相对误
RMSE
差绝对值 M 三个指标评定模型精准度,指标评定结果见表 4。
MRE
表 4 各时序年降水序列模拟模型训练期及验证期模拟性能对比分析
评价指标
时序 项目
确定性系数 均方根误差 平均相对误差绝对值?%
训练期( 1724—1993年) 0.99 20.03 1.98
1724 —2019年
验证期(1994—2019年) 0.92 45.39 7.65
训练期(1813—1993年) 0.99 21.23 2.07
1813 —2019年
验证期(1994—2019年) 0.89 54.33 9.17
训练期( 1951—1993年) 0.98 46.56 4.78
1951—2019年
验证期(1994—2019年) 0.81 78.08 14.08
由表 4可知,由三个时序分别构建的北京地区降水模拟模型在训练期均表现出较高水平的模拟精
度,其中 1724—2019年序列误差最小,1951—2019年序列误差最大,三个随机模拟模型确定性系数
2
R均达 0.98,平均相对误差绝对值 M 均小于 5%,除 1951—2019年模型外,其余时序模型均方根误
MRE
差 R RMSE 均小于 25。验证期精度虽低于训练期,但三个随机森林模拟模型平均相对误差绝对值小于
15%,确定性系数均达 0.80以上,其中 1724—2019年序列误差最小,1813—2019年序列在均方根误
4
— 6 9 —