
Page 7 - 2023年第54卷第8期
P. 7
是第 i个核函数;
式中:m为核函数的数量,一般采用试错法来确定 m,其范围一般为 1~5;函数 φ i
w
Y为 MDN对应权重参数的输出信息。
常用的核函数为高斯核函数,公式为:
1 (X - μ) 2
i
(Y X) = - 2 (4)
φ i e 2 σ
i
槡 2 πσ i
σ
式中:μ为期望值;σ为方差,采用指数函数处理,σ = exp (Y),以保证为非负值函数。
MDN的输出变量 Y元素个数为 3m。
f
μ
μ
w
w
σ
Y= [Y,…,Y ,Y ,…,Y ,Y σ ,…,Y ] (5)
m + 1
2m
3m
2m + 1
1
f
m
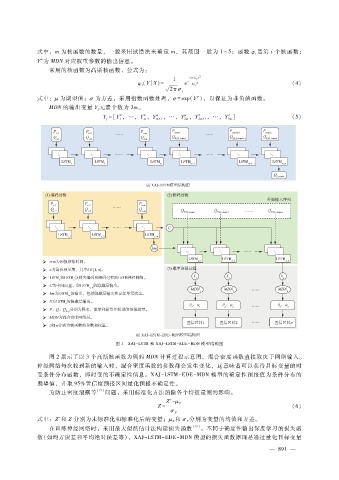
图 1 XAJ - LSTM和 XAJ - LSTM- EDE - MDN模型结构图
图 2展示了以 3个高斯核函数为例的 MDN计算过程示意图。混合密度函数直接取决于网络输入。
神经网络每次收到新的输入时,混合密度函数的参数都会发生变化,这意味着可以获得目标变量的时
变条件分布函数,即时变的不确定性信息。XAJ - LSTM- EDE - MDN模型的确定性预报值为条件分布的
期望值,并取 95%置信度预报区间量化预报不确定性。
为防止密度泄露等 [19] 问题,采用标准化方法消除各个特征量纲的影响。
Z′ - μ Z
Z = (6)
σ Z
分别为变量的均值和方差。
式中:Z′和 Z分别为未标准化和标准化后的变量;μ Z 和 σ Z
在训练神经网络时,采用最大似然估计法构建损失函数 [19] 。不同于确定性输出深度学习的损失函
数(如均方误差和平均绝对误差等),XAJ - LSTM- EDE - MDN模型的损失函数原理是通过量化目标变量
— 8 9 1 —