
Page 68 - 2024年第55卷第5期
P. 68
4 案例研究
本文选用水布垭面板堆石坝为研究对象,坝
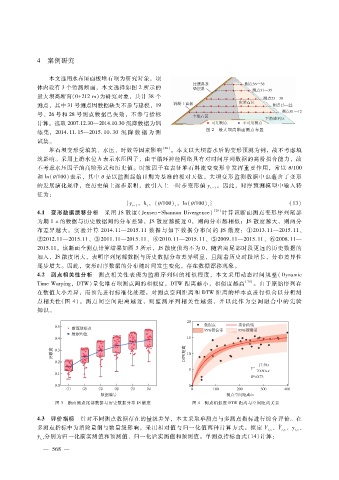
体内设有 3个监测断面,本文选择如图 2所示的
最大坝高断面( 0 + 212m)为研究对象,共计 38个
测点,其中 31号测点因数据缺失不参与建模,19
号、26号和 28号测点数据已失效,不参与指标
计算。选取 2007.12.30—2014.10.30沉降数据为训
图 2 最大坝高断面测点布置
练集,2014.11.15—2015.10.30沉 降 数 据 为 测
试集。
堆石坝变形受填筑、水压、时效等因素影响 [28] 。本文以大坝蓄水后的变形预测为例,故不考虑填
筑影响。采用上游水位 h表示水压因子,由于循环神经网络具有对时间序列数据的高阶拟合能力,故
不考虑水压因子的高阶形式和历史值。时效因子在表征堆石料流变变形中发挥重要作用,常以 θ ?100
和 ln( θ ?100)表示,其中 θ 是以监测起始日期为基准的相对天数。大坝变形监测数据中也蕴含了变形
的发展演化规律,在历史值上逐步累积,故引入上一时步变形值 y 。因此,时序预测模型中输入特
t - 1
征为:
{y ,h,( θ ?100),ln( θ ?100)} (13)
t - 1 t t t
4.1 变形数据漂移分析 采用 JS散度(Jensen - ShannonDivergence) [29] 计算该断面测点变形序列尾部
为期 1a的数据与历史数据间的分布差异,JS散度越接近 0,则两分布越相似;JS散度越大,则两分
布差异 越 大。实 验计算 2014.11—2015.11数 据与如下 数 据分 布 间 的 JS散 度:① 2013.11—2015.11、
②2012.11—2015.11、③2011.11—2015.11、④2010.11—2015.11、⑤2009.11—2015.11、⑥2008.11—
2015.11。该断面全测点计算结果如图 3所示,JS散度值均不为 0,随着离尾部时段更远的历史数据的
加入,JS散度增大,表明序列尾部数据与历史数据分布差异明显,且随着历史时段增长,分布差异性
逐步增大。因此,变形时序数据的分布随时间发生变化,存在数据漂移现象。
4.2 测点相关性分析 测点相关性表现为监测序列间的相似程度,本文采用动态时间规整(Dynamic
TimeWarping ,DTW)量化堆石坝测点间的相似度,DTW 距离越小,相似度越高 [30] 。由于原始序列存
在数值大小差异,需预先进行标准化处理。对测点空间距离和 DTW 距离的样本点进行拟合以分析测
点相关性(图 4)。测 点间 空 间 距 离 越 近,则 监 测 序 列 相 关 性 越 强,并 以 此 作 为 空 间 融 合 中 的 先 验
知识。
图 3 断面测点尾部数据与历史数据分布 JS散度 图 4 测点相似度 DTW 距离与空间距离关系
4.3 评价指标 针对不同测点数据存在的量级差异,本文采取单测点与多测点指标进行综合评价。在
^
多测点指标中为消除量纲与数量级影响,采用相对值与归一化值两种计算方式。拟定 Y 、Y 、y 、
i,t
i,t
i,t
^ 分别为归一化前实测值和预测值、归一化后实测值和预测值。单测点指标由式(14)计算:
y
i,t
— 5 6 —
8