
Page 124 - 水利学报2025年第56卷第3期
P. 124
基于反演结果构建 S4测点渗压预测代理模型。以上游水位作为输入,渗压测值作为输出,选取
900.00m至 908.45m范围内的上游水位值与其对应的有限元计算结果作为训练数据建立模型,所选上
游水位范围涵盖了水库的特征水位,模型构建方法同反演代理模型一致。经多次寻优结果稳定不再变
化时,RBF渗压预测代理模型的扩展速度和隐层神经元个数分别为 spread = 1.026 ,MN= 5 。根据计算
结果可知以该反演结果构建 S4测点处渗压预测代理模型,存在固有误差 e = 0.45m ,将其用于修正机
理模型,得到机理模型预测结果与残差时间序列如图 9所示。机理模型能较好的预测出该测点渗流压
力变化趋势,可解释性强,物理意义明确,但在预测结果精度上存在明显的预测误差,且残差序列中
仍隐含有趋势性及周期性等关键信息,这是机理模型自身固有的不足导致的,这部分需要通过借助深
度学习模型进行修正。
表 4 反演结果有限元计算值与实测值对比
测点 实测值?m 计算值?m 绝对误差?m 相对误差?%
S1 902.16 901.58 - 0.58 - 0.06
S2 899.84 899.18 - 0.66 - 0.07
S3 893.81 894.64 0.83 0.09
S4 894.44 893.99 - 0.45 - 0.05
图 9 SSA - RBF代理模型预测结果与残差时间序列图
4.4 数据驱动模型构建
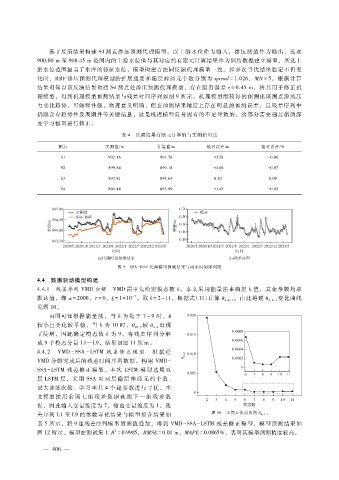
4.4.1 残差序列 VMD分解 VMD需事先给定模态数 k,本文采用能量法来确定 k值,其余参数均取
- 7
默认值,即 α = 2000 ,τ = 0 ,ξ = 1 × 10 。取 k = 2~11 ,根据式(11)计算 θ k,k - 1 。由此得到 θ k,k - 1 变化曲线
见图 10。
由图可知根据能量法,当 k为处于 7~9时,θ
出现
较小且变化较平稳,当 k为 10时,θ 10,9 较 θ 9,8
了陡增,因此确定模态数 k为 9。将残差序列分解
成 9个模态分量 L1—L9,结果如图 11所示。
4.4.2 VMD- SSA- LSTM 残 差 修 正 模 型 根 据 经
VMD分解完成后的残差时间序列数据,构建 VMD -
SSA - LSTM 残差修正模型。本次 LSTM 模型选用双
层 LSTM层,采 用 SSA对 两层 隐 层 神 经 元 的 个 数、
最大训练次数、学习率共 4个超参数进行寻优。本
文模型使 用 前 面 七 组 残 差 数 据 预 测 下 一 组 残 差 数
据,因此输入变量维度为 7,输出变量维度为 1。残
差序列 L1至 L9的参数寻优结果与模型拟合结果如 图 10 不同 k值对应的 θ k,k - 1
表 5所示,将 9组残差序列模型预测值叠加,得到 VMD - SSA - LSTM 残差修正模型,模型预测结果如
2
图 12所示。模型在测试集上 R = 0.9905 ,RMSE = 0.01m ,MAPE = 0.0865%,表明其模型预测精度较高。
6
— 4 0 —