
Page 47 - 2021年第52卷第7期
P. 47
3.3.2 ARMA(1,2)模型 ARMA(1,2)模型的阶数为 p = 1、q = 2 ,由式(26)、(27)可知整体变量 H
1 - φ 2
可表示为 H = 1 ,各相依变异程度所对应的整体变量 H 的取值范围见表 6。
1 + θ + θ 2
2
1 2
表 6 ARMA(1,2)模型各相依变异程度区间所对应的整体变量 H 的取值范围
1 - φ 2
H = 1 取值范围 相关系数 r 取值范围 相依变异程度
1 + θ + θ 2
2
1 2
(0.9222,1.0000] [0.0000,0.2789) 无变异
(0.8891,0.9222] [0.2789,0.3331) 弱变异
(0.6400,0.8891] [0.3331,0.6000) 中变异
(0.3600,0.6400] [0.6000,0.8000) 强变异
(0.0000,0.3600] [0.8000,1.0000) 巨变异
此种条件下,分别在相依变异的 5 个等级对应的整体变量 H 区间内各取一组满足条件的 φ 、
1
θ 、 θ 组合值,同时一阶自回归系数 φ 、一阶滑动平均系数 θ 以及二阶滑动平均系数 θ 还需满足式
1 2 1 1 2
(28)的限制条件。选取的 5 组系数值分别为 φ = 0.02 、 θ = 0.07 、 θ = 0.08 , φ = 0.15 、 θ = 0.18 、
1 1 2 1 1
θ = 0.20 , φ = 0.30 、 θ = 0.28 、 θ = 0.30 , φ = 0.50 、 θ = -0.50 、 θ = -0.40 , φ = 0.80 、
2 1 1 2 1 1 2 1
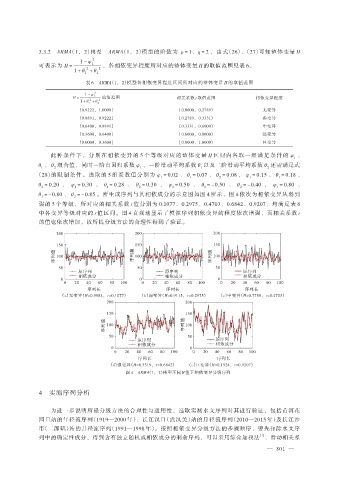
θ = -0.80 、 θ = -0.85 。所生成序列与其相依成分的示意图如图 4 所示,图 4 依次为相依变异从弱到
1
2
强的 5 个等级,所对应的相关系数 r 值分别为 0.1077、0.2975、0.4703、0.6842、0.9207,均满足表 6
中各变异等级对应的 r 值区间。图 4 直观地显示了模拟序列相依变异的程度依次增强,而相关系数 r
的值也依次增加,故所提分级方法的合理性得到了验证。
200 200 200
150 150 150
序列值 100 序列值 100 序列值 100
50 50 50
原序列 原序列 原序列
相依成分 相依成分 相依成分
0 0 0
0 20 40 60 80 100 0 20 40 60 80 100 0 20 40 60 80 100
序列长 序列长 序列长
(a)无变异(H=0.9884,r=0.1077) (b)弱变异(H=0.9115,r=0.2975) (c)中变异(H=0.7788,r=0.4703)
200 200
150 150
序列值 100 序列值 100
50 50
原序列 原序列
相依成分 相依成分
0 0
0 20 40 60 80 100 0 20 40 60 80 100
序列长 序列长
(d)强变异(H=0.5319,r=0.6842) (e)巨变异(H=0.1524,r=0.9207)
图 4 ARMA(1,2)模型不同 H 值下相依变异分级序列
4 实测序列分析
为进一步说明所提分级方法的合理性与适用性,选取实测水文序列对其进行验证,包括黄河花
园口站的年径流序列(1919—2000 年)、长江汉口(武汉关)站的月径流序列(2010—2015 年)及长江沙
市(二郎矶)站的月径流序列(1991—1998 年)。按照相依变异分级方法的步骤顺序,要先扣除水文序
[1]
列中的确定性成分,得到含有独立随机或相依成分的剩余序列,可以采用综合加权法 、滑动相关系
— 801 —